


I. Introduction à AndroMDA pour Java : concepts d'architecture▲
Comprendre de nouveaux outils et de nouvelles technologies peut être une tâche effrayante. AndroMDA n'est pas une exception. Ce tutoriel vise donc à être une présentation en douceur de la puissance d'AndroMDA. Nous allons vous guider pas à pas dans l'installation de votre environnement de développement et bâtir une première application Java. Au lieu de passer mécaniquement à travers une série d'étapes, nous allons nous concentrer sur les idées et les concepts. Avec cette connaissance, vous serez prêt à affronter les défis du monde réel. Alors n'hésitez pas à mettre de côté une demi-journée ininterrompue de concentration pour comprendre les bases d'AndroMDA, parce qu'il y a beaucoup à apprendre. Et puis préparez-vous une bonne tasse de café avant de plonger avec nous dans le monde merveilleux de l'architecture pilotée par le modèle.
Vous allez découvrir beaucoup de choses au cours de ce voyage, beaucoup de concepts assez abstraits et d'éléments qui dépassent de loin les considérations de langages ou les détails d'implémentation. C'est d'ailleurs une chose qui effraie souvent ceux qui découvrent MDA pour la première fois : on se demande comment cela peut servir concrètement à quelque chose. C'est là que je vous demande de me faire confiance : encore une fois, j'utilise AndroMDA quotidiennement, sur mes projets personnels et professionnels, parce qu'il me permet de gagner du temps, tout en concevant des logiciels de meilleure qualité. Ça ne sera pas évident tout de suite, alors un peu de patience et à la fin, soit vous vous demanderez comment vous avez pu programmer avant, soit vous rejetterez tout en bloc. Mais au moins, dans le deuxième cas, ça sera en toute connaissance de cause. Quand les auteurs vous conseillent de vous réserver une demi-journée et de prendre un bon café, c'est pour évoquer cette patience et cette concentration du début : apprendre AndroMDA, c'est beaucoup plus court que d'apprendre un langage ou un framework, mais cela demande un peu plus de concentration et surtout d'ouverture d'esprit, parce que le but est de développer différemment. Alors en voiture… !
Commençons donc par passer en revue quelques concepts fondamentaux qui forment la base des applications d'entreprises moderne. Après avoir évoqué ces concepts, nous verrons comment AndroMDA les implémente dans les applications qu'il génère.
I-A. Architecture des applications▲
Les applications d'entreprises modernes sont communément basées sur l'utilisation de plusieurs composants, chacun fournissant une fonctionnalité particulière. Les composants qui fournissent des services similaires sont généralement regroupés en couches, eux-mêmes organisés en une pile dans laquelle les composants d'une couche donnée utilisent les services des composants de la couche en dessous (ou ceux des composants de la même couche).
Pour ceux qui seraient familiers avec la théorie des réseaux, vous connaissez certainement le modèle OSI (« Open Systems Interconnection »), ou alors vous aurez peut-être entendu parler de la « pile TCP/IP » ? Et bien l'architecture applicative en couches est basée sur les mêmes principes. Mais si vous n'en avez jamais entendu parler, peut-être comprendrez-vous mieux le principe avec les schémas ci-dessous.
Le diagramme ci-dessous illustre une structure en couches très populaire pour une application d'entreprise :
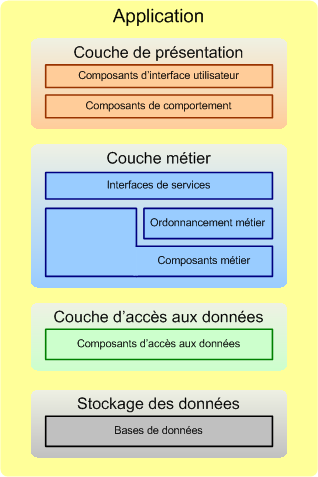
- La couche de présentation contient les composants qui doivent interagir avec l'utilisateur de l'application, comme les pages Web, les formulaires, ainsi que tout ce qui régit le comportement de l'interface utilisateur.
- La couche métier intègre les fonctionnalités et les traitements propres à l'application. Les fonctionnalités simples peuvent être implémentées avec des composants sans états, alors que les transactions complexes et longues peuvent utiliser des composants d'ordonnancement avec états. Les composants métier sont généralement dissimulés derrière une sous-couche d'interface de service qui agit comme une façade afin de dissimuler la complexité de l'implémentation. Cela participe de ce que l'on appelle communément une architecture orientée par les services (SOA = « Service-Oriented Architecture »).
- La couche d'accès aux données fournit une interface simple pour accéder aux données et les manipuler. Les composants de cette couche abstraient la sémantique de la couche de données sous-jacente, permettant ainsi à la couche métier de ce concentrer sur la logique applicative. Chaque composant fournit typiquement des méthodes pour créer, lire, mettre à jour et effacer (CRUD = « Create, Read, Update, Delete ») des entités de données.
- La couche de stockage des données comprend l'ensemble des sources de données de l'application d'entreprise. Les deux types les plus communs de sources de données sont les bases de données et les systèmes de fichiers.
Il est important de noter que ces couches ne sont que des regroupements logiques de composants qui constituent une application. La façon dont ces couches sont matérialisées dans un environnement matériel et logiciel réel peut varier de façon importante en fonction de plusieurs facteurs. Dans un scénario très simple, toutes ces couches peuvent résider sur une seule et même machine. Dans un autre un peu plus complexe (mais assez commun), la couche de présentation peut se trouver par exemple sur la station de travail de l'utilisateur final, les couches métier et d'accès aux données sur un serveur d'applications, et les bases de données sur un serveur dédié à cet usage.
Un argument que l'on entend souvent contre l'utilisation d'MDA en tant que concept est le fait qu'il s'adapte à très peu d'applications réelles, ce qui rend du même coup l'investissement en temps nécessaire à son apprentissage relativement peu utile. Pourtant, l'architecture d'application exposée ci-dessous est extrêmement courante : on parle souvent d'architecture n-tier pour la désigner, chaque tier correspondant à une couche. Et vous allez voir dans la suite de cet article comment MDA en tant que méthode, et AndroMDA en tant qu'outil, s'adaptent particulièrement dans cette situation courante et vous font gagner un temps précieux par rapport à une façon de faire plus traditionnelle, et même par rapport à l'utilisation de générateurs de code classiques.
I-B. L'architecture des applications générées par AndroMDA▲
Maintenant que nous avons évoqué les concepts de base derrière les applications d'entreprise modernes, voyons ensemble comment AndroMDA implémente ces concepts.
AndroMDA prend en entrée un modèle métier spécifié en UML (« Unified Modeling Language ») et génère des parties importantes des couches nécessaires pour construire une application Java. La faculté d'AndroMDA à traduire automatiquement des spécifications métier haut niveau en un code de qualité permet un gain de temps significatif dans l'implémentation d'applications Java.
En fait, l'idée qui se cache derrière MDA en tant que méthode, et donc derrière AndroMDA en tant qu'outil, c'est de se dire que la plus grande partie d'une application doit pouvoir être conçue indépendamment de la technologie utilisée pour l'implémenter. Le résultat de cet effort de conception, ce sont des modèles qui peuvent être spécifiées dans un langage standard, et lui aussi indépendant de la technologie d'implémentation : UML. Ensuite, la démarche la plus simpliste est de partir de ces modèles pour les traduire manuellement en leur implémentation en fonction de la technologie utilisée, ce qui est souvent très long et très facilement source d'erreurs inutiles et d'incohérences. Il se trouve justement qu'avec l'expérience, on a pu identifier des schémas de conception (plus connus dans leur dénomination anglophone de « design patterns ») génériques, qui permettaient de résoudre des problèmes classiques, de proposer une solution éprouvée qu'il suffisait de réutiliser. On s'est aussi rend compte que l'implémentation de ces modèles dans une technologie donnée était automatisable dans une certaine mesure. C'est ce que fait AndroMDA : il extrait toutes les informations qu'il peut d'un modèle UML, y applique un ensemble de modèles de conception et de paramètres de configuration pour produire tout le code générique d'une application, ne laissant au développeur qu'à boucher les trous en implémentant les parties qui n'ont pas pu être spécifiées dans le modèle, notamment parce qu'elles dépendaient de la technologie d'implémentation choisie. La part de code généré dans le code intégral de votre application dépend donc de deux facteurs : le niveau de détail de votre modèle et sa conformité avec les attentes d'AndroMDA d'une part, et le nombre et la qualité des modules de génération mis en œuvre par AndroMDA d'autre part. Ça peut encore vous paraître très abstrait, mais vous allez voir : c'est réellement bluffant, d'autant qu'on s'attend souvent à ce qu'un générateur de code produise un code assez « sale », parsemé de variables numérotées et autres commentaires codés. Mais avec AndroMDA, ce n'est pas du tout le cas grâce à ses importantes possibilités de configuration et à l'utilisation de modèles de conception standards.
Le diagramme ci-dessous met en correspondance les différentes couches applicatives identifiées précédemment avec les technologies Java supportées par AndroMDA.
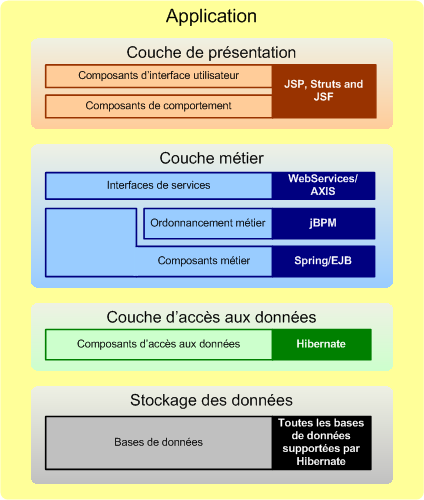
- Couche de présentation : AndroMDA offre actuellement un choix entre deux technologies pour implémenter des couches de présentation web : Struts (plus d'infos ici et là, ou encore ici) et JSF. Il accepte en entrée des diagrammes d'activité UML pour spécifier les enchaînements de pages, et génère des composants pour les frameworks Struts ou JSF.
- Couche métier : la couche métier générée par AndroMDA est principalement consituée de services configurés en utilisant le framework Spring (plus d'infos ici). AndroMDA crée des méthodes vides dans les classes d'implémentation où la logique métier peut être ajoutée. Les services générés peuvent éventuellement être interfacés avec des EJB. Dans ce scénario, les services doivent être déployés dans un conteneur d'EJB comme JBoss AS. Les services peuvent également être exposés comme des WebServices, fournissant une interface indépendante de la plateforme aux clients qui souhaitent accéder à leurs fonctionnalités. AndroMDA peut aussi générer des processus et des ordonnancements métier pour le moteur d'ordonnancement jBPM (qui fait partie de la famille de produits JBoss).
- Couche d'accès aux données : AndroMDA s'appuie sur le très populaire outil de mapping objet relationnel Hibernate pour la génération de la couche d'accès aux données des applications. Il produit des objets d'accès aux données (DAO pour « Data Access Objects ») pour les entités définies dans le modèle UML. Ces objets d'accès aux données utilisent l'interface de programmation d'Hibernate pour convertir les champs de bases de données en objets et vice-versa.
- Bases de données : puisque les applications générées par AndroMDA utilisent Hibernate pour accéder aux données, vous pouvez utiliser n'importe quelle base de données supportée par Hibernate.
Deux choses importantes à ajouter après ce paragraphe. D'abord, puisqu’AndroMDA est totalement modulaire, il est fondamentalement extensible et il y a de très nombreuses possibilités d'ajout de modules qui génèreront une implémentation pour des technologies propres à votre environnement. Et comme AndroMDA est développé selon un modèle ouvert, la seule limite réelle c'est votre imagination. Bien sûr, développer certains plugins peut être une tâche ardue, mais tout est une question de rentabilité de l'investissement. D'ailleurs, l'équipe d'AndroMDA a créé récemment une nouvelle initiative pour coordonner et encourager la création de modules additionnels. Sachez par exemple qu'un effort important est en cours pour finaliser une pile de modules pour .NET, qui devrait à terme vous permettre de générer à votre convenance une application Java et/ou .NET à partir des mêmes modèles. Vous commencez à entrevoir l'intérêt ? Enfin, il est important de remarquer que, contrairement à certains générateurs de code classiques, AndroMDA ne se contente pas de générer des fichiers de classes Java : il génère également les fichiers de configuration XML traditionnellement nécessaires dans la plupart des frameworks Java, comme les fichiers de mapping d'Hibernate, les fichiers de description de beans de Spring ou encore les fichiers de configuration d'Axis. En fait, ce qui est étonnant, c'est qu'alors même que vous n'avez pas encore bouché les trous d'implémentation, simplement avec votre modèle, AndroMDA génère une application qui compile et peut déjà être déployée sans erreur dans un serveur d'applications ! Bien sûr il manque des fonctionnalités, mais toute l'infrastructure est prête.
I-C. Propagation des données entre les couches▲
Au-delà des concepts évoqués jusqu'à maintenant, il est important de comprendre comment les données se propagent entre les différentes couches d'une application. Commençons du plus bas niveau pour remonter.
Comme vous le savez sans doute, les bases de données relationnelles stockent les données comme des champs dans des tables. La couche d'accès aux données récupère ces champs depuis la base de données et les transforme en objets qui représentent les entités du domaine métier. C'est pourquoi on appelle ces objets des entités métier. La couche d'accès aux données passe les entités métier à la couche métier qui exécute sa logique sur ces entités.
Concernant la communication entre la couche métier et la couche présentation, il y a véritablement deux écoles de pensée. Certains recommandent que la couche de présentation puisse avoir un accès direct aux entités métier, tandis que d'autres préconisent l'inverse : les entités métier devraient être totalement isolées de la couche de présentation et la couche métier devrait encapsuler les données dans ce que l'on appelle des objets de valeur (« value objects ») avant de les transmettre à la couche de présentation. Essayons de comprendre les avantages et les inconvénients de ces deux approches.
La première approche (que des entités, pas d'objets de valeur) est plus simple à implémenter. Vous n'avez pas besoin de créer des objets de valeur ou d'écrire aucun code pour transférer l'information depuis les entités vers les objets de valeur. En fait, pour de petites applications simples où la couche de présentation et la couche métier s'exécutent sur la même machine, cette approche fonctionnera très bien. Mais pour des applications plus grandes et plus complexes, cette approche s'adapte mal, notamment pour les raisons suivantes :
- la logique métier n'est plus contenue exclusivement dans la couche métier. Il est alors tentant de manipuler directement les entités depuis la couche de présentation, et de disperser du même coup la logique métier dans des endroits différents, ce qui peut rapidement devenir un cauchemar en termes de maintenabilité. Et dans le cas où il y a plusieurs interfaces de présentation pour un service (par exemple une interface web, un client riche et un client mobile), la logique métier doit alors être dupliquée dans tous ces clients. De plus, il n'y a rien qui empêche les clients de corrompre les entités, intentionnellement ou pas ;
- lorsque la couche de présentation s'exécute sur une machine différente (par exemple dans le cas d'un client riche), il est complètement absurde de sérialiser tout un réseau d'entités pour l'envoyer au client. Prenons l'exemple de la présentation à l'utilisateur d'une liste de commandes. Dans ce scénario, nous n'avons pas besoin de transmettre tous les détails de chaque commande à l'application cliente. Tout ce dont le client a besoin, c'est d'un numéro de commande, d'une date et d'un montant total pour chaque commande. Ensuite, si l'utilisateur souhaite voir les détails d'une commande en particulier, nous pouvons toujours lui transmettre cette commande en entier ;
- passer des entités réelles au client peut poser un risque de sécurité. Voulez-vous que l'application cliente puisse toujours accéder au salaire dans une entité « Employé » ou à votre marge de profit dans une entité « Commande » ?
Les objets de valeur fournissent une solution pour tous ces problèmes. D'accord, il faut écrire un peu de code en plus, mais en échange vous obtenez une couche métier d'une solidité à toute épreuve qui communique efficacement avec la couche présentation. On peut voir les objets de valeur comme une vision contrôlée cohérente avec les besoins de votre application cliente. Notez d'ailleurs qu'AndroMDA fournit un support de base pour la transformation d'entités en objets de valeur (et vice-versa), comme vous allez le voir dans le tutoriel, un support qui va d'ailleurs encore une fois vous faire gagner beaucoup de temps.
I-D. Services et session Hibernate▲
Un autre concept-clé à propos des applications générées par AndroMDA est la relation forte entre les méthodes de services (c'est-à-dire les opérations exposées par un service) et les sessions Hibernate. Mais avant d'introduire ce concept, nous devons poser quelques bases.
Une session Hibernate est un objet construit à l'exécution de l'application qui permet à cette dernière de créer, lire, mettre à jour et supprimer des entités dans la base de données. Tant que cette session est ouverte, ces entités sont « attachées » à la session et vous pouvez naviguer de l'une à l'autre en utilisant les relations entre elles. Si au cours de cette navigation, vous faites référence à une entité qui n'est pas encore chargée en mémoire, Hibernate va automatiquement la charger pour vous : c'est ce que l'on appelle le chargement paresseux, ou « lazy loading ». Cependant, dès que vous fermez la session Hibernate, les entités en mémoire sont considérées comme « détachées », c'est-à-dire qu'Hibernate n'en a plus aucune connaissance. Vous êtes libre de garder des références vers de telles entités, mais Hibernate ne maintiendra plus le lien entre ces entités et la base de données, et en particulier il ne chargera pas les entités reliées en cas de besoin. Si vous essayez d'accéder à une telle entité accidentellement, vous obtiendrez d'ailleurs une exception « LazyInitializationException ».
Dans ce contexte, parlons de la relation entre une méthode de service et une session Hibernate. Quand une application client appelle une méthode de service, une nouvelle session Hibernate est automatiquement ouverte. Vous n'avez besoin d'écrire aucun code pour ça. De la même façon, lorsque la méthode de service est terminée, la session Hibernate associée est automatiquement fermée. En d'autres termes, la durée de vie d'une session Hibernate correspond exactement au temps d'exécution d'une méthode de service. En conséquence, les entités sont attachées à la session Hibernate pendant toute la durée de l'exécution de la méthode de service, mais pas au-delà. Donc si votre méthode de service retourne des entités, l'application client doit faire extrêmement attention à ne pas accéder à des entités reliées qui ne seraient pas déjà en mémoire. De toute façon, vous pouvez éviter tout cela en suivant la recommandation évoquée précédemment, c'est-à-dire en encapsulant toute l'information nécessaire dans des objets de valeur tant que la session est encore ouverte et passer ces objets de valeur à l'appelant comme valeur de retour. Autrement dit, considérez une méthode de service comme une frontière transactionnelle logique, et faites tout ce que vous avez besoin de faire à l'intérieur de la méthode de service avant de retourner les résultats comme des objets de valeur.
Une autre implication de la relation forte entre une méthode de service et une session Hibernate est que les applications clients ne devraient pas essayer de court-circuiter la couche de service et d'interagir directement avec les couches inférieures. Vous pourrez toujours vous débrouiller pour passer en force et accéder directement aux composants d'accès aux données, mais tôt ou tard vous aurez des problèmes.
I-E. Et maintenant ?▲
Maintenant que vous comprenez la théorie de base d'AndroMDA, le prochain article de cette série sera consacré à la description de l'application que nous allons implémenter dans ce tutoriel.